Advanced Configuration
The AI Peon plugin provides advanced configuration options accessible via Window > Preferences > Peon AI > AI Peon Advanced.
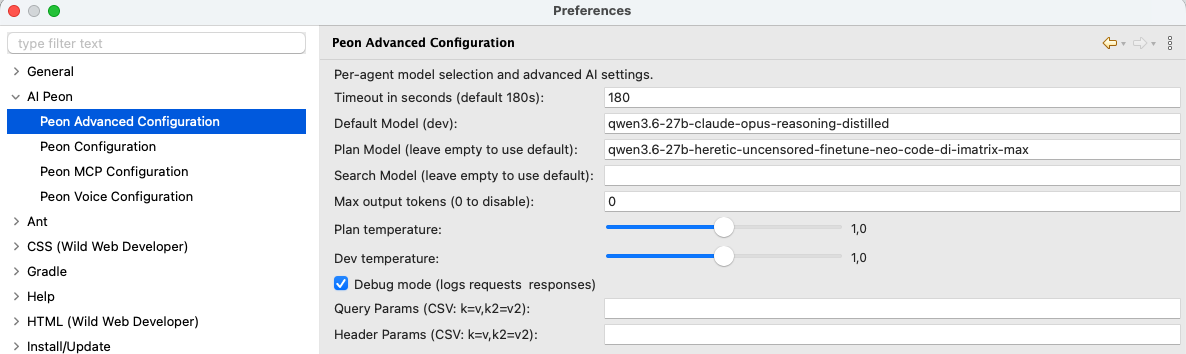
Per-Agent Model Selection
Different agents can use different models to optimize for cost, speed, or capability:
| Agent | Purpose | Recommended Model Type |
|---|---|---|
| Dev (default) | Creating task plans and strategies | Reasoning-capable models (e.g., Sonnet) |
| Plan | Creating task plans and strategies | Reasoning-capable models (e.g., Opus) |
| Search | Finding relevant context and information | Fast, smaller models (e.g., Haiku) |
| Compact | Conversation compression for context management | Fast, smaller models (e.g., Haiku) |
How It Works
- The Dev agent always uses the base model you configure — this is your primary coding model
- Leave a per-agent field empty to use the provider's default for that agent
- Enter a specific model name to override only that agent's model
- Models are validated against your provider's available models when you click "Check Host and Port..."
Temperature Settings
Temperature controls the randomness of model outputs:
| Setting | Range | Effect |
|---|---|---|
| Plan Temperature | 0.6 - 1.0 | Higher = more creative plans; Lower = more deterministic |
| Dev Temperature | 0.2 - 0.6 | Controls code generation creativity (uses base model) |
- Claude and some other models only accept 1.0.
Debug Mode
When enabled, logs all requests and responses to the Eclipse console.
Use cases:
- Troubleshooting connection issues
- Understanding what context is being sent to the model
- Debugging prompt template issues if you create an issue
Query Parameters
Add custom query parameters to API requests (format: key=value,key2=value2):
Example: stream=false,timeout=30
Useful for:
- Provider-specific options not exposed in the UI
- Testing different API behaviors
- Adding custom headers through query strings
Header Parameters
Add custom HTTP headers to requests (format: key=value,key2=value2):
Example: X-Custom-Header=myvalue,Authorization=Bearer token123
Useful for:
- Custom authentication requirements
- Provider-specific features via headers
- Adding tracking or debugging information
Max Output Tokens
Controls the maximum number of tokens in model responses (0 = disable limit): langchain4j and some LLMs default to 1024 -- if you have odd behaviors increase this.
| Setting | Effect |
|---|---|
| Low values (1024) | Short, concise responses; faster generation - may break |
| Recommended low (2048) | Have a short value, limits also the think budget where possible |
| Default nowerdays (4000) | Usually a a good default or with Opus around 8000 |
| Disabled (0) | Provider's default limit applies |
Troubleshooting
Models Not Being Used by Agents
Restart Eclipse after changing preferences