Configuration
After installation, configure the plugin via Window > Preferences > Peon AI.
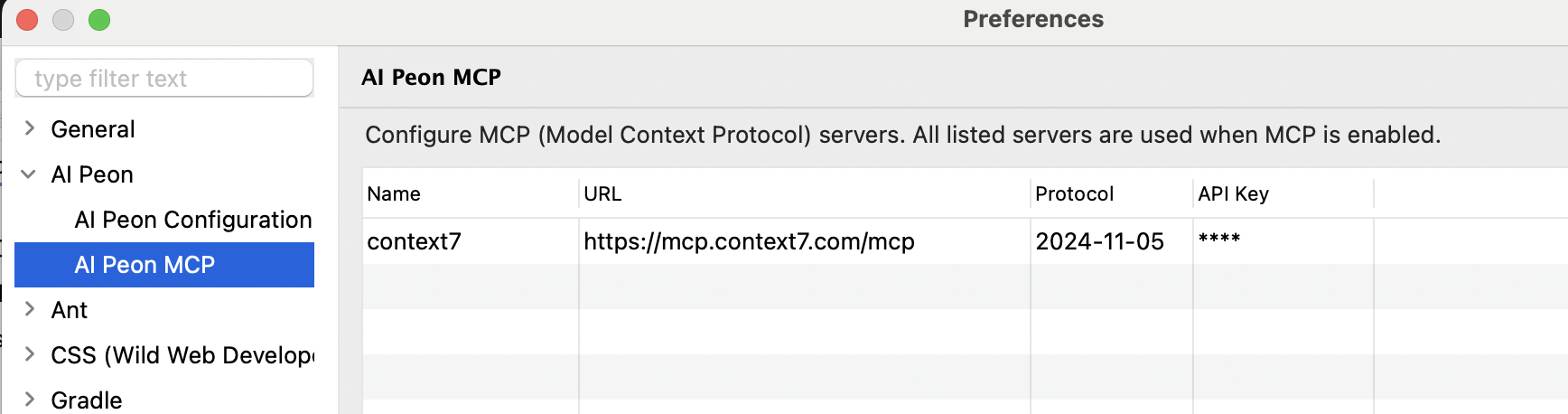
Provider Settings
Ollama
Run models locally e.g. windows.
| Setting | Value |
|---|---|
| Provider | OLLAMA |
| Model | llama3.2, codellama, qwen2.5-coder, mistral |
| Base URL | http://localhost:11434 |
LM Studio
Run models locally — e.g. for MAC.
| Setting | Value |
|---|---|
| Provider | LM Studio / OpenAI HTTP 1.1 |
| Model | qwen/qwen3.5-9b |
| Base URL | http://localhost:1234/v1 |
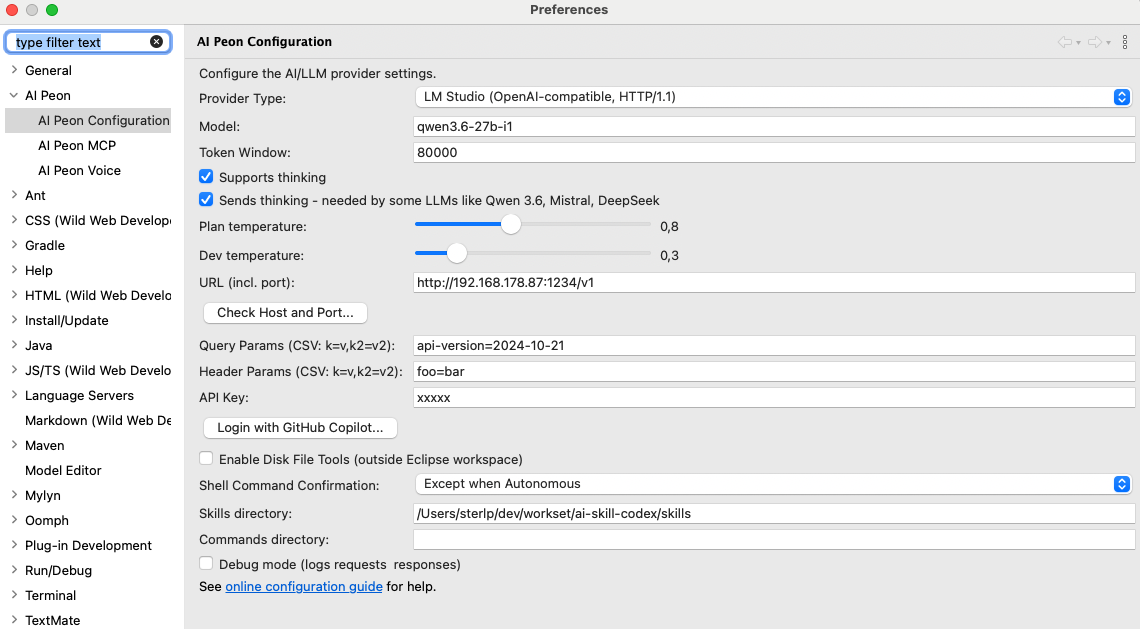
OpenAI
| Setting | Value |
|---|---|
| Provider | OPEN_AI |
| Model | gpt-4o, gpt-4o-mini, o3-mini |
| Base URL | https://api.openai.com/v1 |
| API Key | Your OpenAI API key |
OpenAI-compatible APIs
Any OpenAI-compatible server (LM Studio, OpenRouter, LocalAI, vLLM, …) works by changing the Base URL. Set the API Key to a dummy value like none if the server does not require one.
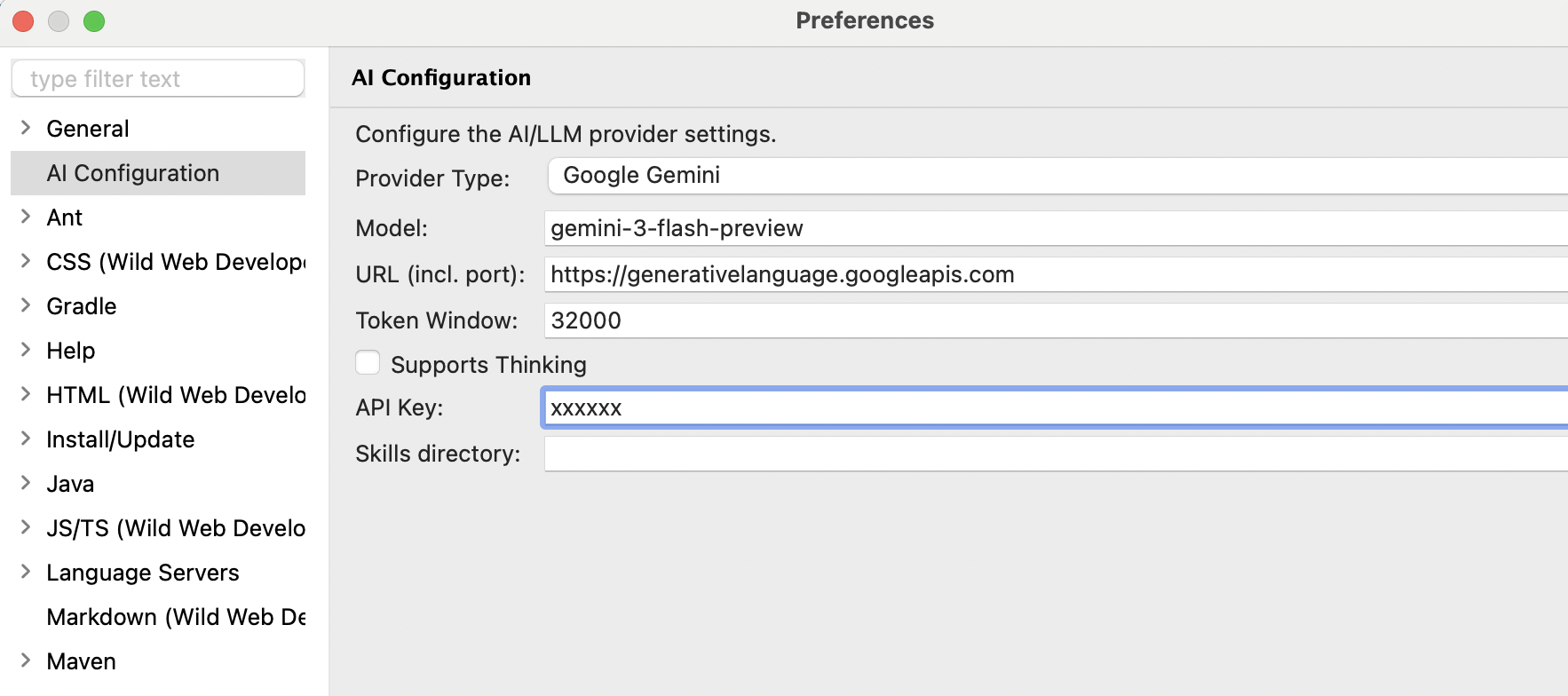
Google Gemini
| Setting | Value |
|---|---|
| Provider | GOOGLE_GEMINI |
| Model | gemini-2.0-flash, gemini-2.5-pro-preview-03-25 |
| Base URL | (leave empty) |
| API Key | Your Google AI Studio API key |
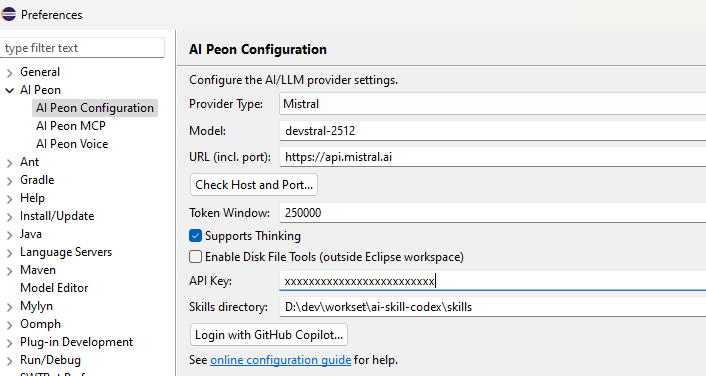
Mistral AI
| Setting | Value |
|---|---|
| Provider | MISTRAL |
| Model | mistral-large-latest, mistral-small-latest, codestral-latest |
| Base URL | (leave empty) — set https://api.mistral.ai in Voice preferences if using voice input |
| API Key | Your Mistral API key |
GitHub (Marketplace)
Using the GitHub Models marketplace with pay-per-use billing.
| Setting | Value |
|---|---|
| Provider | GitHub (PAT) |
| Model | Varies; use model picker to list available models |
| Base URL | https://models.inference.ai.azure.com (default) or custom endpoint |
| API Key | Your GitHub Personal Access Token (PAT) with models:read scope |
Authentication:
- Generate a GitHub PAT with
models:readscope - Paste the token in the API Key field
- Click "Check Host and Port..." to verify connectivity
Available models: Use the Model picker to list all marketplace models you have access to. Models are filtered to those supporting tool calling only.
GitHub Copilot (Subscription)
Access Claude Sonnet, Claude Opus, Claude Haiku, GPT-5, and more as a GitHub Copilot subscriber.
| Setting | Value |
|---|---|
| Provider | GitHub Copilot (subscription) |
| Model | Claude Sonnet, Claude Opus, Claude Haiku, GPT-4o, GPT-5-mini, etc. |
| Base URL | (leave empty for github.com; enter custom domain for GitHub Enterprise) |
| API Key | (leave empty; OAuth token obtained via login button) |
Authentication:
- Click Login with GitHub Copilot... button in the preferences
- Select GitHub deployment type (github.com or GitHub Enterprise)
- Complete the device flow authorization in your browser
- The plugin stores your OAuth token and auto-selects the
GITHUB_COPILOTprovider - Use the Model picker to list available Copilot models (Sonnet, Opus, etc.)
Requirements:
- Active GitHub Copilot subscription (Individual $10/month, Business, or Enterprise)
- Copilot access enabled on your GitHub account
Model availability: Models listed depend on:
- Your Copilot subscription tier
- Regional availability
- GitHub's current model catalog
Difference: Marketplace vs. Subscription
| Marketplace (PAT) | Copilot (OAuth) | |
|---|---|---|
| Product | GitHub Models marketplace | GitHub Copilot subscription |
| Auth method | Personal Access Token | OAuth Device Flow |
| Billing | Pay-per-use | Monthly subscription |
| Models | Public marketplace catalog | Copilot subscriber models (Claude, GPT-5) |
| Provider name | GITHUB_MODELS | GITHUB_COPILOT |
| Use case | One-off testing, marketplace exploration | Primary AI assistant with Copilot benefits |
Advanced Settings
Token Window
The Token Window setting controls how many tokens of conversation history are sent to the AI model with each request. This is configured in the preference page as an integer field and stored in LlmConfig.tokenWindow.
| Setting | Value |
|---|---|
| Preference Key | llm.tokenWindow (PREF_TOKEN_WINDOW) |
| Default Value | 16000 tokens |
| Type | Integer |
| Editor Component | IntegerFieldEditor in AiConfigPreferenceView |
Configuration Flow
graph LR
A[User sets value in UI] --> B[Eclipse Preference Store<br/>ScopedPreferenceStore]
B --> C[LlmConfig.tokenWindow field]
C --> D1[Provider buildChatModel()<br/>limits context sent to LLM]
C --> D2[TemplateContext.setTokenWindow()<br/>available as ${tokenWindow}]Key Points:
- Value is stored in Eclipse
ScopedPreferenceStorewith instance scope - Retrieved by
LlmConfig.tokenWindow()field (default: 16000) - Used by provider's
buildChatModel()for context window limits - Also set in
TemplateContextas template variable${tokenWindow}
Template Variable Integration
The token window is available as a template variable ${tokenWindow} in prompt templates, allowing dynamic reference to the configured limit:
// Example usage in system prompts or instruction templates
String systemPrompt = "Keep responses within ${tokenWindow} tokens.";This enables agent personas and instruction templates to respect context boundaries defined by the user.
Important Distinction: Token Window vs Message Memory Buffer
| Component | Purpose | Limit | Configurable |
|---|---|---|---|
| Token Window | Context sent to AI provider | ~16000 (configurable) | Yes - via this setting |
| Message Memory Buffer | Internal conversation history storage | 500,000 messages | Fixed in MessageWindowChatMemory |
Explanation: The token window limits what context is sent to the LLM for each request, while the message memory buffer stores conversation history internally. A user can have a large internal history but only send the most recent tokens within their configured window to the AI model.
How It Works
- User sets token window value in preferences
- Value stored in
ScopedPreferenceStoreunder keyllm.tokenWindow - When chat service starts,
LlmConfig.newConfig()initializes with default 16000 (or loaded from prefs) - Each request includes up to
tokenWindowtokens of conversation history - AI provider may adjust based on their own limits
Practical Guidance
Recommended Values by Use Case:
| Value Range | Use Case | Trade-offs |
|---|---|---|
| 1000-2000 | Simple queries, coding tasks, one-off requests | Fast responses, lower costs, limited context awareness |
| 2000-16000 | General conversation, most everyday use cases | Balanced approach, good context retention without excessive latency |
| 16000-8192 | Complex multi-turn conversations, long discussions | Best for referencing earlier messages, may increase latency and costs |
Provider-Specific Context Limits
Different AI providers have different maximum context window capabilities:
| Provider | Typical Maximum | Notes |
|---|---|---|
| Ollama (local) | 2048-4096 (model dependent) | Check specific model documentation; varies by quantization |
| OpenAI gpt-4o | Up to 128,000 tokens | Generous limits; token window setting often irrelevant for these models |
| LM Studio | Model-dependent | Depends on underlying model configuration in LM Studio UI |
| Google Gemini | Up to 1M+ tokens (some models) | Check specific model documentation |
| Mistral AI | Varies by model | Typically 32K-128K context windows |
Recommendation: For local providers (Ollama, LM Studio), set token window close to their default. For cloud providers with large context windows (OpenAI, Gemini), you can set higher values if needed for long conversations.
Important Considerations
Token counting includes both directions: The token window counts both user messages AND AI model responses in the conversation history.
Provider auto-truncation: If you set a value larger than your provider supports, they may:
- Automatically truncate older messages (silently)
- Reject the request with an error
- Return degraded responses
Check provider documentation: Before setting very high values, verify your specific model's maximum context window in the provider's documentation.
Testing recommended: After changing token window, test with a longer conversation to ensure the AI can reference earlier messages correctly.
Token estimation vs actual tokens: The value you set is an estimate; actual token counts vary by language and model encoding.
Thinking Support
The Supports Thinking option enables models that support "thinking" or chain-of-thought reasoning, allowing them to show intermediate reasoning steps before generating final responses. This is useful for complex problem-solving tasks where you want to see the model's thought process.
Testing the Connection
- Open the Peon AI chat view
- Type a test message like "Hello"
- If configured correctly, you should receive a response
Troubleshooting
If connection tests fail, verify:
- The server is running and accessible at the specified URL
- Firewall settings allow connections to the port
- For local servers (Ollama, LM Studio), ensure they're started before testing